
1. Introduction
At Leena AI, we’re on a mission to transform how enterprises access and leverage institutional knowledge. Our Agentic AI platform, powered by WorkLM, helps hundreds of organizations deliver exceptional employee experiences by making critical information instantly accessible across ERP, CRM, HRIS, ITSM, and other business systems through a single conversational interface.
Central to this mission is our ability to process and understand complex documents, particularly PDFs, which remain the backbone of enterprise knowledge management. From HR policies and financial reports to technical specifications and compliance manuals, PDFs encapsulate the institutional memory that powers daily operations. However, extracting accurate, structured information from these documents at enterprise scale poses unique technical hurdles.
Over the past quarter, our engineering team undertook an ambitious overhaul of our PDF parsing pipeline. We set out to enhance extraction accuracy, dramatically increase throughput, and robustly handle the growing volume of enterprise documents. The result is a future-proof pipeline delivering up to 22% improvement in layout detection, 5× gains in processing speed, and a 6% uplift in identifying mission-critical visuals. This deep dive covers the technical innovations across four core components: layout detection, image classification, caption generation, and table extraction.
2. Background: The Challenge
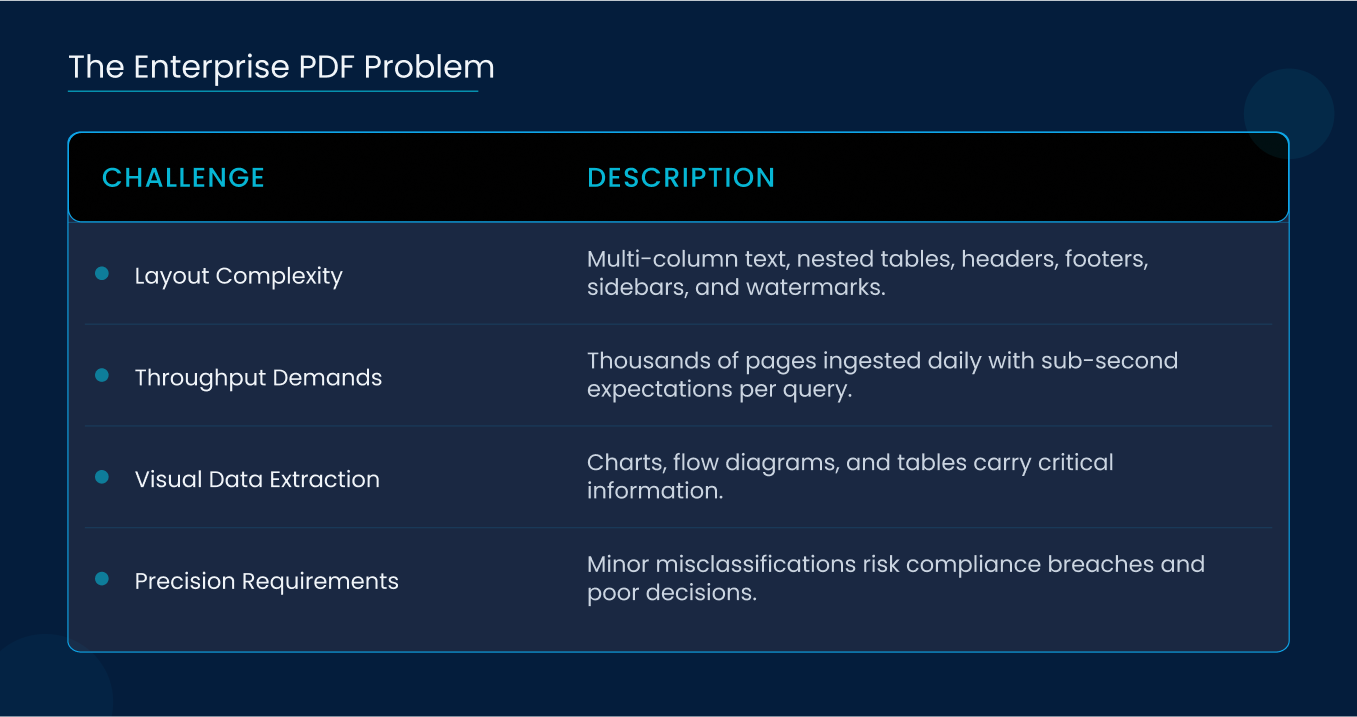
2.1 The Enterprise PDF Problem
PDFs were designed for consistent visual rendering, not semantic structure. Key challenges include:
- Heterogeneous Layouts: Multi-column text, nested tables, headers and footers, sidebars, footnotes, and watermarks.
- Throughput Demands: Thousands of pages ingested daily with sub-second expectations on individual queries.
- Visual Data Extraction: Charts, flow diagrams, and tables carry critical information that must be understood, not merely located.
- Precision Requirements: Even minor misclassifications can lead to compliance breaches or flawed business decisions.
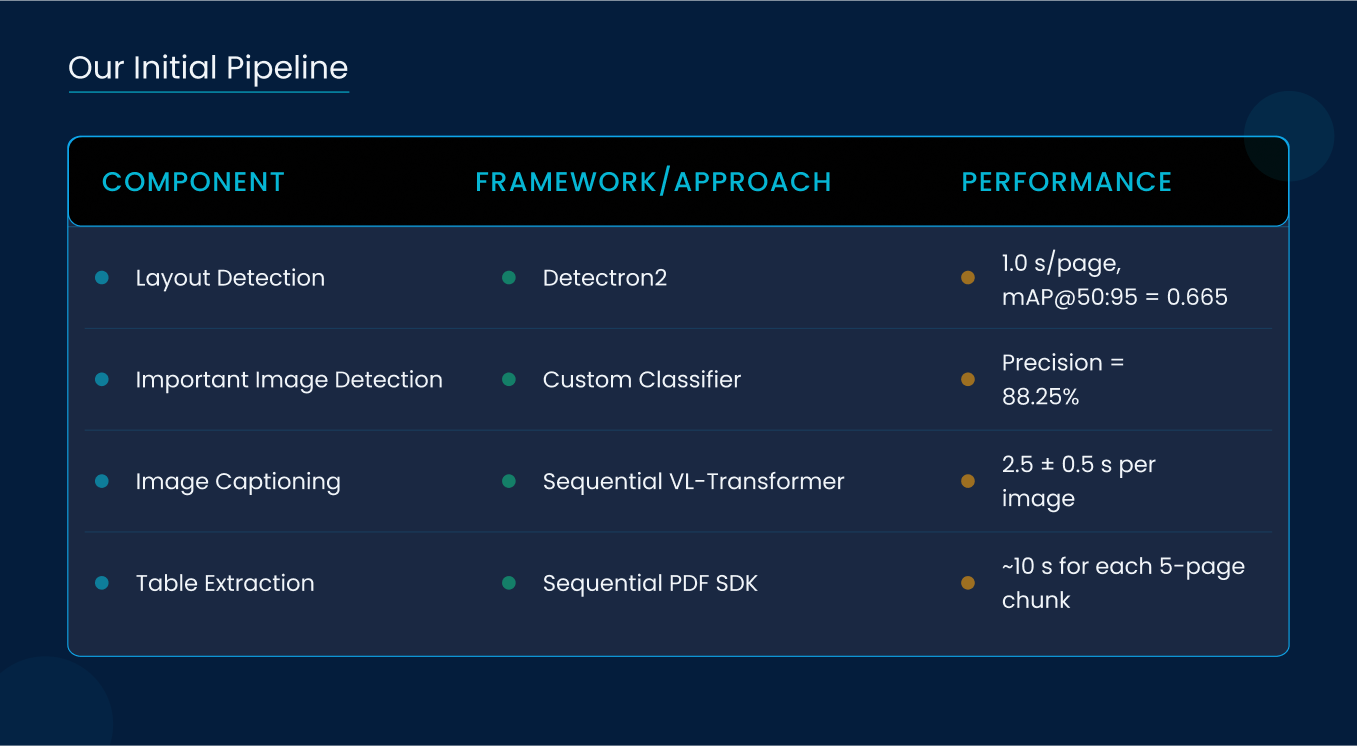
2.2 Our Initial Pipeline
Our legacy stack used Facebook’s Detectron2 for layout detection, followed by sequential image captioning and table parsing modules. Key baseline metrics:
- Layout Detection Speed: 1.0 s/page
- Layout mAP@50:95: 0.665
- Important Image Precision: 88.25%
- Image Caption Latency: 2.5 ± 0.5 s/image
- Table Parsing: Sequential, ~10 s for each 5-page chunk
As document volumes and SLAs tightened, these bottlenecks became untenable.
2.3 Setting Our Goals
We defined four measurable objectives:
- Precision: Increase layout detection mAP@by ≥15%
- Latency: Reduce per-page processing to ≤0.3 s
- Visual Understanding: Boost important image detection accuracy to ≥90%
- Parallelism: Architect end-to-end flow for concurrent extraction without sacrificing reliability

3. Core Layout Detector Model Upgrade
3.1 Model Transition: Detectron2 to In-house Model
We evaluated several architectures, Detectron2, EfficientDet, and Model variants, against enterprise-specific metrics for small-object recall and inference cost on GPU and FPGA. The in-house model emerged as optimal due to its depthwise separable convolutions, anchor-free detection heads, and streamlined inference graph.
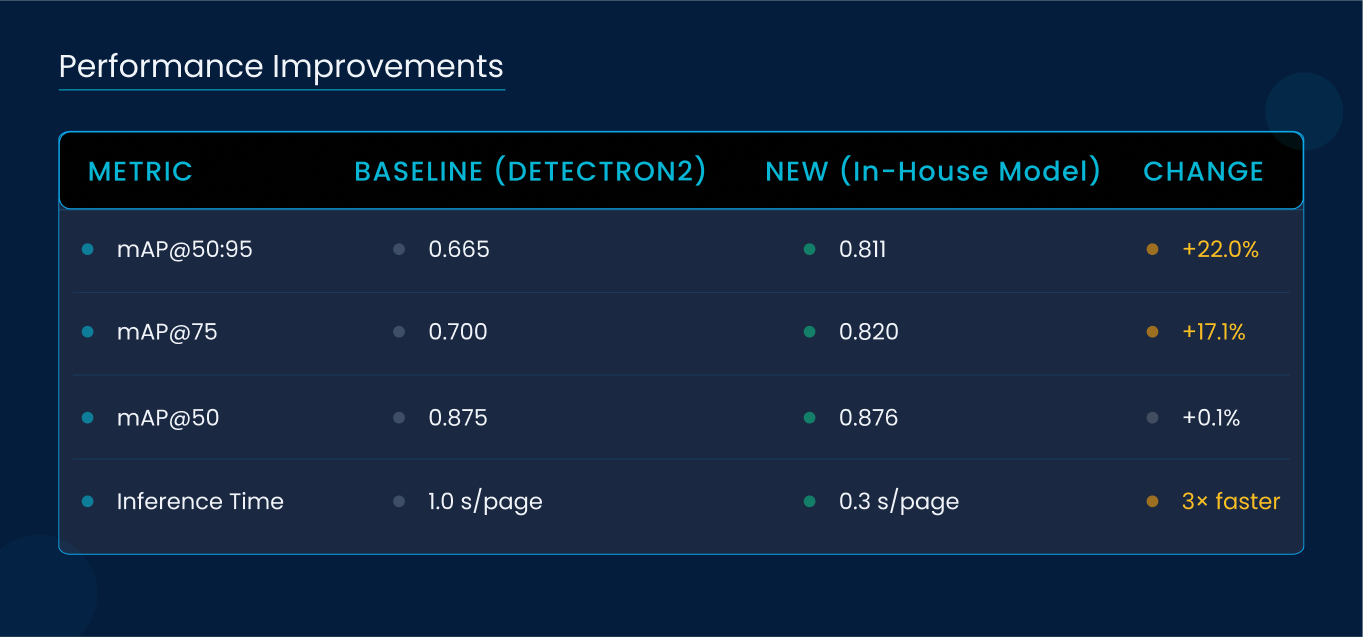
3.2 Performance Improvements
Benchmarking on 5,500 annotated pages from diverse enterprise domains, in-house model delivered:
This upgrade cut CPU/GPU cycles per page by 60%, reducing cloud compute costs under heavy load.
3.3 Impact on Bounding Box Localization
Higher IoU at stricter thresholds means:
- Downstream Accuracy: Table regions and image crops align precisely with source content, eliminating partial extractions.
- Pipeline Robustness: Fewer false positives reduce error-handling overhead and re-processing loops.
- Developer Velocity: Clear, consistent region proposals simplified feature-flag rollouts for new document types.

4. Important Image Detector Model Enhancement
4.1 Fine-tuning Approach
We assembled a taxonomy of “important” visuals, charts, organizational diagrams, regulatory stamps, and annotated 10,000 images from enterprise PDFs. Using transfer learning, we fine-tuned a ResNet-based classifier with custom focal loss to address class imbalance.
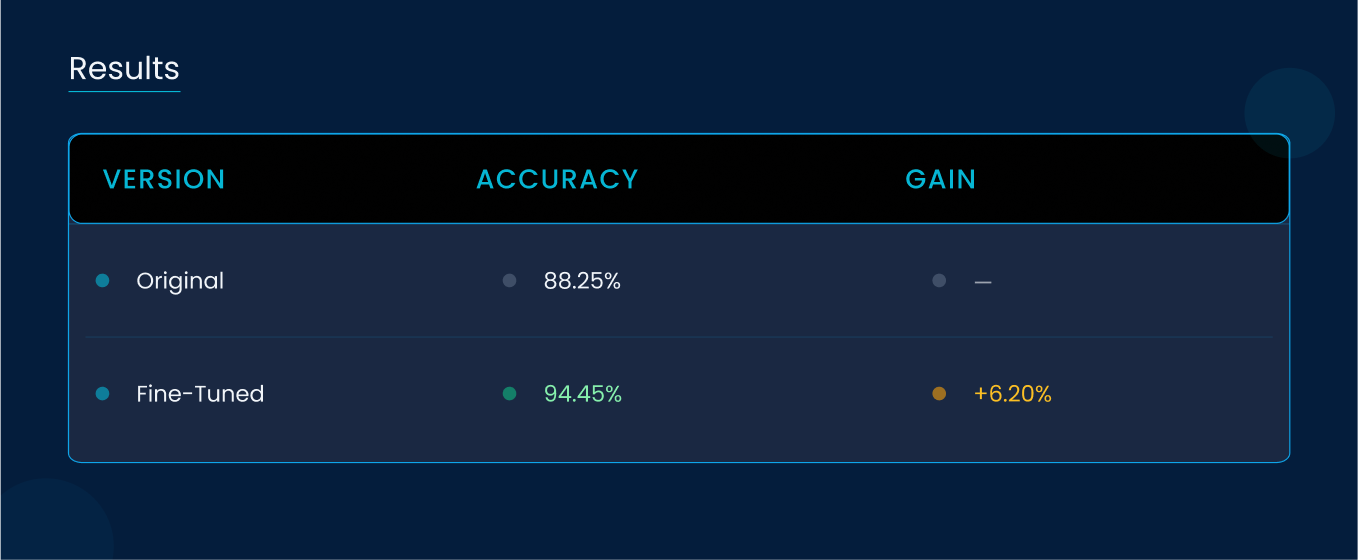
4.2 Results
Evaluation on a 1,694-image holdout set showed:
- Original Accuracy: 88.25%
- Fine-tuned Accuracy: 94.45%
- Absolute Gain: +6.20%
4.3 Real-world Impact
Accurate filtering of non-essential graphics ensures:
- Relevance: Notification cards and decorative icons are dropped.
- Clarity: Users see only context-bearing visuals in chat responses.
- Performance: Captioning and downstream NLP models focus compute on high-value inputs.

5. Image Captioning Parallelization
5.1 The Bottleneck
Legacy caption generation, powered by a large Vision-Language Transformer, ran sequentially, introducing up to 3 s of delay per page with multiple images.
5.2 Optimization Strategy
By batching ten images per request and leveraging asynchronous inference on GPU clusters, we amortized model-warm-up costs and maximized hardware utilization. We containerized the caption service with a scale-out policy based on queue length.
5.3 Performance Gains
- Before: 2.5 ± 0.5 s/image
- After: 0.7 ± 0.2 s/image (4× faster)
This enables full-page parsing, including text, images, and tables, in under 0.4 s.
6. Tables Parallelization
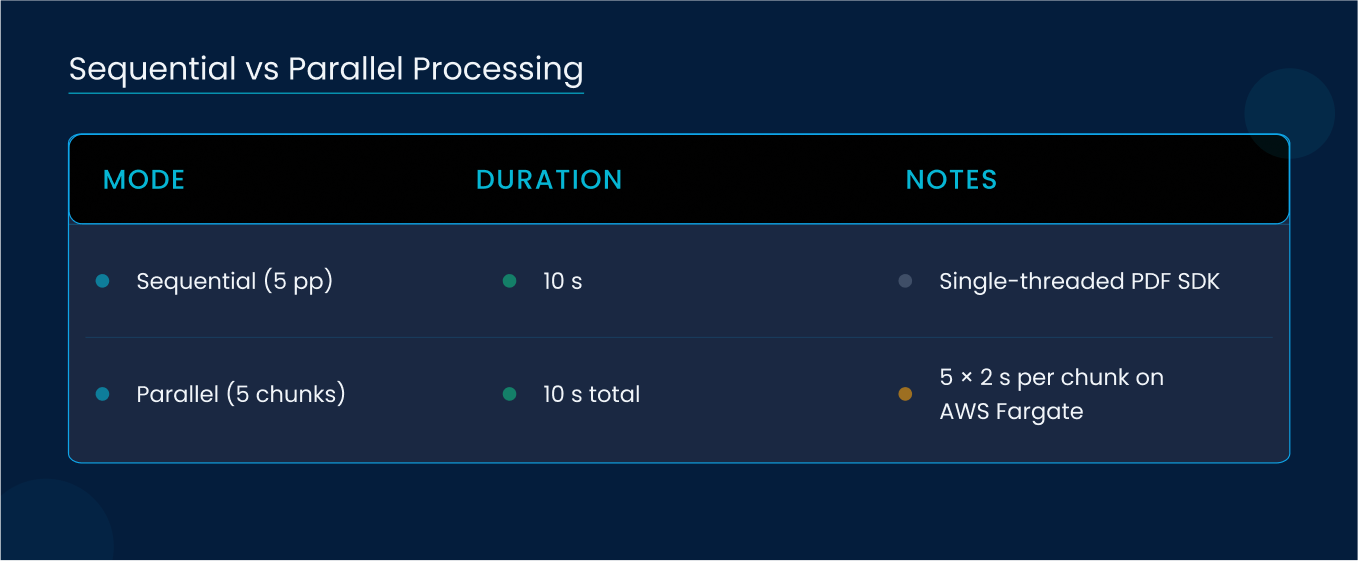
6.1 Sequential vs Parallel Processing
Chaptered table extraction previously ran in sequence, processing each 5-page chunk in ~10 s.
6.2 Architecture Changes
We decomposed the table parser into stateless microservices using Docker on AWS Fargate. Each service ingests a chunk of pages, extracts tables via an optimized PDF SDK, and writes JSON schemas to S3. A Lambda function collates results and triggers downstream indexing.
6.3 Results
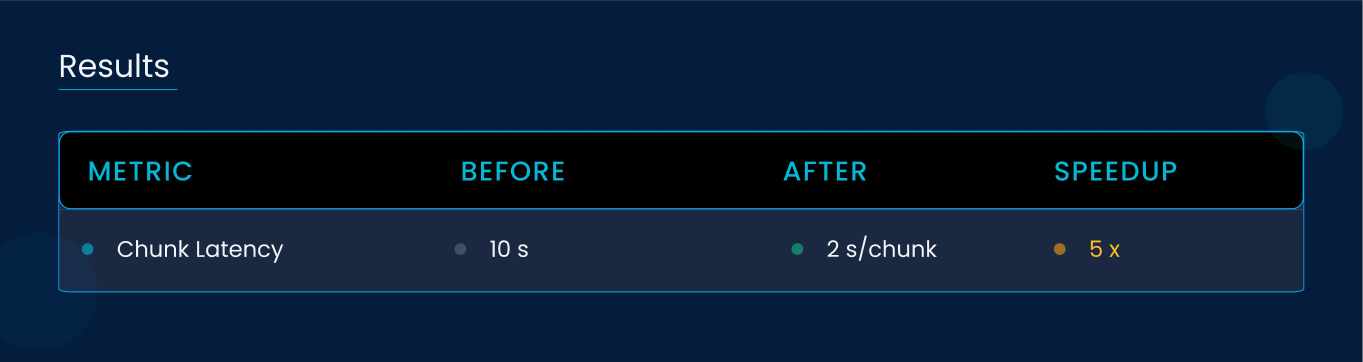
Horizontal scaling matches document influx, preserving SLA under peak loads.
7. Combined Impact & System Performance
Integrating these enhancements, our end-to-end pipeline now:
- Throughput: Processes pages at 2.5 pages/second per GPU
- Latency: Sub-page parse time of <0.4 s
- Accuracy: 0.811 mAP@50:95 for layouts, 94.45% for image relevance
- Cost Efficiency: 40% reduction in cloud compute spend
These metrics translate to near-instant ticket ingestion, instant knowledge retrieval, and predictable costs at scale.

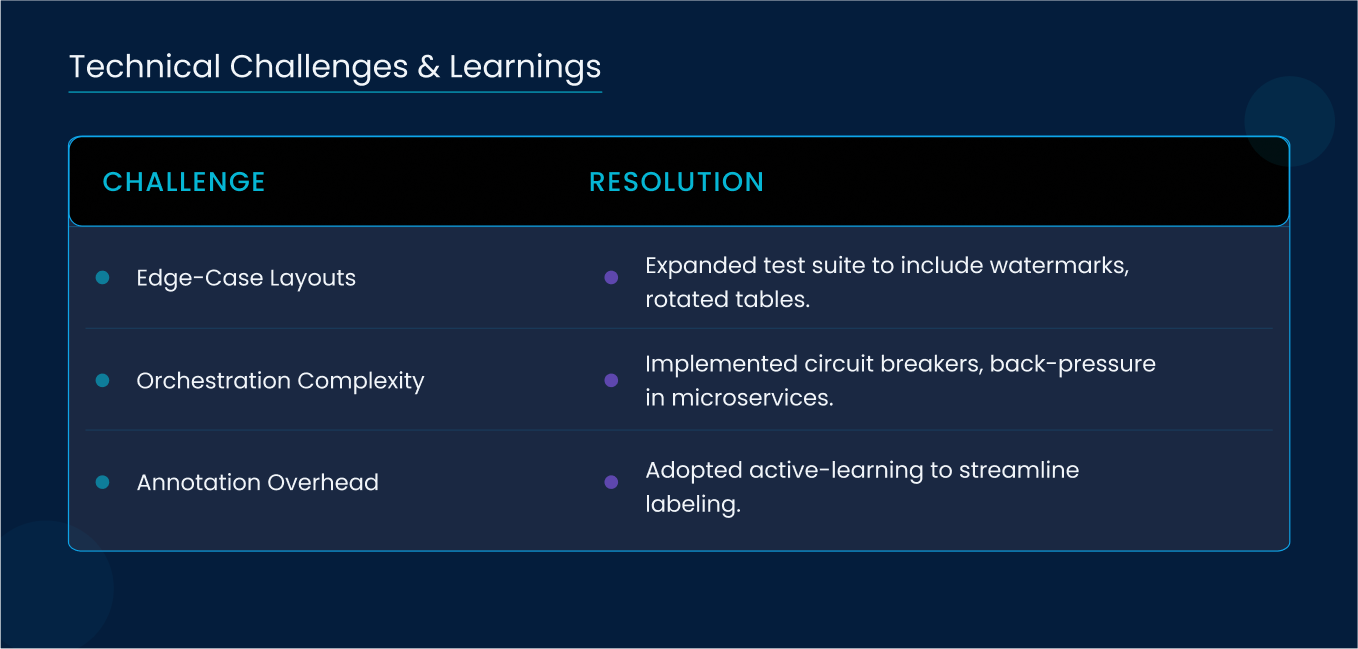
8. Technical Challenges & Learnings
- Model Benchmarking: Crafting enterprise-focused test suites revealed edge cases, watermarks, rotated tables, that generic datasets miss.
- Concurrency Orchestration: Building idempotent, fault-tolerant microservices required circuit breakers and back-pressure mechanisms.
- Annotation Overhead: High-quality labels drove accuracy gains but demanded rigorous QA and active-learning workflows.
9. Future Work
- Handwriting Recognition: Integrate on-device inference for scanned notes and forms.
- Multilingual Parsing: Deploy language-agnostic OCR and semantic models for global enterprises.
- Active Learning Loop: Capture user feedback in real time to auto-retrain models on misclassifications.

10. Conclusion
Leena AI’s revamped PDF parsing pipeline delivers enterprise-grade accuracy, speed, and scale, crucial for IT, Finance, and HR systems that demand real-time knowledge access. By combining advanced object detection, fine-tuned classifiers, and massively parallel microservices, we empower CIOs and CTOs to reduce resolution times, cut costs, and unlock actionable insights from institutional knowledge. Experience the future of document processing at https://leena.ai and explore further innovations on our blog.