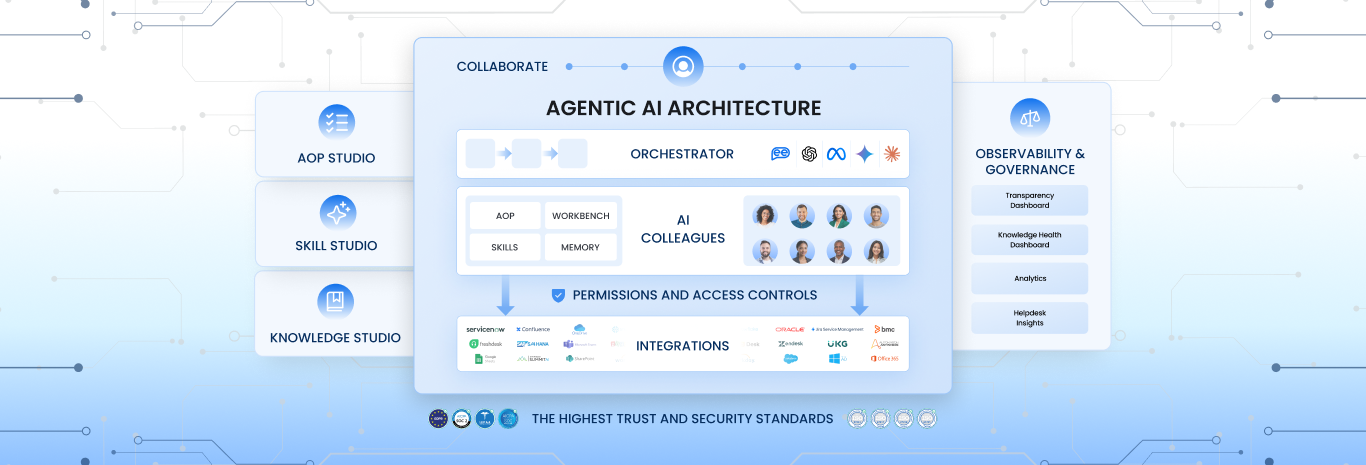
Introduction
In today’s competitive landscape, the standard, off-the-shelf AI chatbot is quickly becoming obsolete. It can answer basic questions, but it doesn’t truly understand your business. For technology leaders, the next frontier isn’t just about artificial intelligence; it’s about creating specialized intelligence. This is where the strategic process of fine tuning llm (Large Language Models) comes in. It’s the key to transforming your internal support systems from simple responders into proactive, autonomous problem-solvers that deliver real business value. This guide will walk you through what fine tuning an LLM means and why it’s a critical strategy for your 2025 roadmap.
What is fine tuning llm and Why Should You Care?
As a leader, you’re focused on outcomes like efficiency, cost reduction, and employee productivity. The process of fine tuning llm directly impacts these goals. It’s not just a technical tweak; it’s a fundamental business decision that turns a generic tool into a bespoke, high-performance asset.
Understanding Fine-Tuning in LLMs
Imagine hiring a brilliant, Ivy League graduate. They have a massive amount of general knowledge (that’s the pre-trained LLM). However, they don’t know your company’s specific software, internal acronyms, or the unique way your finance team handles expense reports. The process of onboarding and training this new hire on your company’s specific playbooks is exactly like fine tuning llm.
We take a powerful, general-purpose model and train it further on your own private data. This could be your historical IT tickets, your internal knowledge base, or your HR policy documents. As a result, the model doesn’t just give a generic answer; it gives the right answer for your organization. This specialized knowledge is the first step in moving from a simple Q&A bot to a truly intelligent agent. The goal of fine tuning llm is to create this specialized expert.
Exploring the Methods of fine tuning llm
The method used for fine tuning llm depends on the specific goal. While the underlying technology is complex, the concepts are straightforward. Each method provides a different way to teach the model how to best serve your employees and organization.
Methods of Fine-Tuning: Supervised, Unsupervised, and Instruction-Based
Think of these as different teaching styles for your new AI employee. Supervised fine-tuning is the most common. It’s like giving the model a stack of flashcards. You show it thousands of your past IT support tickets (the “problem”) and their corresponding solutions (the “answer”). Through this process, it learns the specific patterns of your organization’s issues.
Unsupervised fine-tuning, on the other hand, involves giving the model a large body of your internal text, like your entire Confluence or SharePoint library, and letting it learn the language, style, and jargon of your company on its own.
Finally, Instruction-based fine-tuning is about teaching the model to follow specific commands relevant to your workflows. You provide it with examples like, “If a user asks for access to Salesforce, follow these three steps.” This is crucial for building reliable, automated processes and a core component of a successful fine tuning llm strategy.
The Game Changer: Efficient fine tuning llm
One of the biggest historical barriers to fine tuning llm was the immense cost. It required massive amounts of computing power, akin to renting out an entire data center. Fortunately, recent innovations have made this process dramatically more efficient and affordable, putting it within reach for enterprise-wide deployment.
Parameter-Efficient Fine-Tuning (PEFT) and Its Benefits
Traditional fine-tuning tries to update the entire “brain” of the LLM, which can have billions of parameters. Parameter-Efficient Fine-Tuning (PEFT) is a smarter approach. Instead of changing the entire brain, it freezes the original model and adds a small, new layer of “neurons” to be trained.
Imagine you have a 1,000-page encyclopedia. Instead of rewriting the entire book to add information about your company, you just write a new 10-page chapter and insert it. This is far faster, cheaper, and requires significantly less computational power. Consequently, PEFT makes the fine tuning llm process accessible without needing a team of specialized AI researchers or a massive hardware budget. It’s a pragmatic solution for a real-world business environment.
Fine-Tuning with QLoRA: A Practical Approach
QLoRA (Quantized Low-Rank Adaptation) is a leading-edge PEFT method that takes efficiency even further. To put it simply, it uses clever compression techniques to reduce the memory footprint of the model during training. This means you can achieve incredible results from fine tuning llm using much less expensive, off-the-shelf hardware.
For a CIO or CTO, the implications are huge. QLoRA removes the barrier of astronomical infrastructure costs, making it feasible to create and maintain multiple custom-tuned models for different departments, one for IT, one for HR, and one for Finance, without breaking the bank. It democratizes the power of fine tuning llm.
Real-World Impact of fine tuning llm
Theory is great, but as technology leaders, we live in the world of application and results. The true power of fine tuning llm is realized when it moves beyond answering questions and starts autonomously solving problems, a concept known as Agentic AI.
Applications of Fine-Tuned LLMs in Real-World Scenarios
A generic chatbot might tell an employee how to reset their password. An agentic system, powered by a properly fine-tuned LLM, will do it for them. After authenticating the user’s identity, it will interact with your internal systems to perform the password reset, update the ticket, and confirm with the employee.
Consider a more complex scenario. An employee reports that a critical application is slow. A generic model is useless here. However, a model fine-tuned on your system logs and architecture diagrams can correlate the report with real-time performance data, identify a struggling database server, and automatically file a high-priority ticket with the correct engineering team, complete with all the necessary diagnostic information. This proactive capability, achieved through fine tuning llm, is what separates a cost center from a strategic enabler.
How Leena AI Utilizes Fine-Tuned LLMs for Enhanced Employee Experience
At Leena AI, we have built our platform around this agentic philosophy. Our approach to fine tuning llm is purpose-built for the enterprise. We don’t just create a chatbot; we create autonomous agents that resolve employee issues from end to end.
For example, our IT agent can handle complex, multi-step tasks like new-hire onboarding. It can provision accounts in Office 365, grant access to specific Slack channels, set up a Salesforce license, and schedule orientation meetings, all from a single request in a chat interface. This is possible because we utilize advanced fine tuning llm techniques to teach our models your organization’s specific processes and how to securely interact with your existing applications. This is the core of our “Agentic AI in IT” solution, turning your service desk into an instant, autonomous resolution engine.
Navigating the Risks of fine tuning llm
With great power comes great responsibility. Using your proprietary data for fine tuning llm requires a robust governance and security strategy. As a leader, you must be confident that your company’s sensitive information is protected throughout the process.
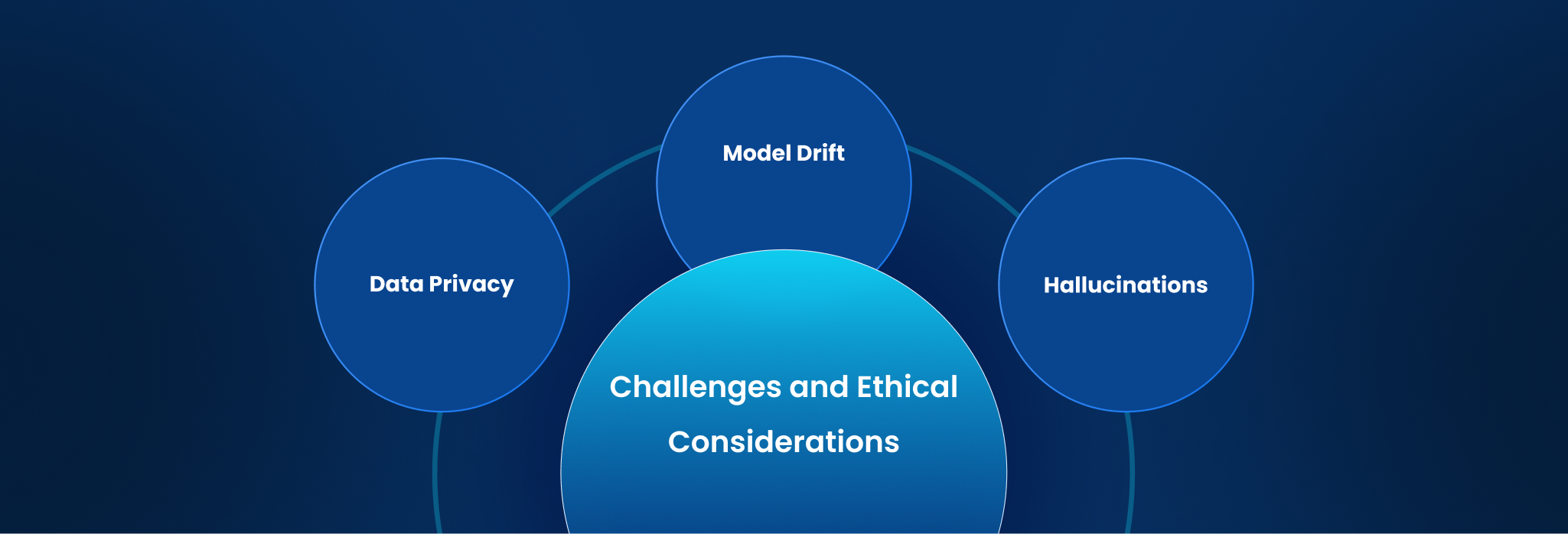
Challenges and Ethical Considerations in Fine-Tuning
The primary challenge is data privacy. Your ticketing data contains names, emails, and potentially sensitive business information. A critical step in any fine tuning llm project is rigorous data anonymization to protect employee privacy and prevent the model from leaking confidential data.
Another challenge is “model drift,” where the model’s accuracy degrades over time as your company’s processes and software change. This requires continuous monitoring and periodic re-tuning to ensure its responses remain accurate and helpful. Finally, you must guard against “hallucinations,” where the model generates confident but incorrect information. A strong fine tuning llm process includes creating robust guardrails to prevent the AI from taking incorrect actions on critical systems.
Frequently Asked Questions (FAQs)
What is the primary benefit of fine tuning llm for enterprise IT support?
The main benefit is transforming your support from reactive to proactive and autonomous. A fine-tuned model understands your specific environment, enabling it to resolve complex issues end-to-end, which reduces resolution time and improves employee productivity.
How much data is needed for an effective fine tuning llm project?
While more data is generally better, modern techniques like PEFT allow for effective fine tuning llm with surprisingly small, high-quality datasets. Even a few thousand examples of specific problems and their solutions can create a highly specialized model.
Is the process of fine tuning llm secure for sensitive company data?
Yes, when done correctly. A secure fine tuning llm process involves hosting the model in a private environment (like a Virtual Private Cloud), implementing rigorous data anonymization techniques, and ensuring no proprietary data is shared with third-party model providers.
How does fine tuning llm differ from retrieval-augmented generation (RAG)?
RAG is like giving the model an open-book test; it “looks up” information from a knowledge base to answer a question. Fine tuning llm is like teaching the model the material so it becomes an expert itself. Fine-tuning internalizes knowledge for faster, more nuanced responses and is better for teaching the model skills and processes.
What is the typical ROI we can expect from a fine tuning llm initiative?
The ROI from fine tuning llm comes from several areas: reduced mean time to resolution (MTTR), lower operational costs from ticket deflection, increased employee productivity from less downtime, and improved employee satisfaction. Many organizations see a significant return within the first year.
How do we ensure the model stays up-to-date after the initial fine tuning llm process?
Maintaining a fine-tuned model requires a continuous feedback loop. This involves regularly retraining the model on new tickets and updated documentation, as well as having human experts review its performance and provide corrective feedback.
Can we perform fine tuning llm for different departments like HR and Finance?
Absolutely. One of the key benefits is creating specialized experts. You can use fine tuning llm to build a model that is an expert on your IT policies and another that is an expert on your HR benefits and payroll systems, ensuring employees always get accurate, context-aware answers.